AI Benchmarks
Benchmark Conditions
The benchmarks are recorded against three chained real-world tests that perform the same tasks demonstrated in our tutorial videos.
- Test 1: Test Register and Activate Account [view task file] [view task video]
- Test 2: Test New Subscription Route [view task file] [view task video]
- Test 3: Test Route Listener [view task file] [view task video]
The test dependency chain (node order and prerequisites) is defined separately in [preset-context.json].
The agent is configured for maximum token efficiency and low error tolerance:
MAX_SNAPSHOTS_HISTORY=0
CONTEXT_COMPRESSION=true
MAXIMUM_RESTRICTED_TOOL_USAGE=3
RATE_LIMIT_RETRY=2
AI_MAX_TOKENS=8192
Models compared: claude-sonnet-4-6 vs deepseek-v4-pro
Results Summary
| Claude | DeepSeek | |
|---|---|---|
| Result | ✓ success | ✓ success |
| Total API Costs | $1.66 | $0.04* |
- Deekseek v4 pro api tokens were offered at a 90% discount when benchmarked.
Verdict
Claude Sonnet 4.6 is the stronger choice for speed and reliability. it completed the full suite faster, maintained lower output verbosity, and showed more consistent behaviour across longer tests. Its cache warmed up more gradually.
DeepSeek V4 Pro's main strength is cost efficiency. it achieved a higher cache hit rate quickly and used fewer API calls in longer tests due to less granular verification. Its weaknesses are higher per-call latency, more frequent instruction violations, and slightly higher output verbosity.
Recommendations
Use DeepSeek V4 pro for development testing or high-volume runs. Use Claude Sonnet 4.6 for regression testing or websites requiring strict compliance.
Execution Duration
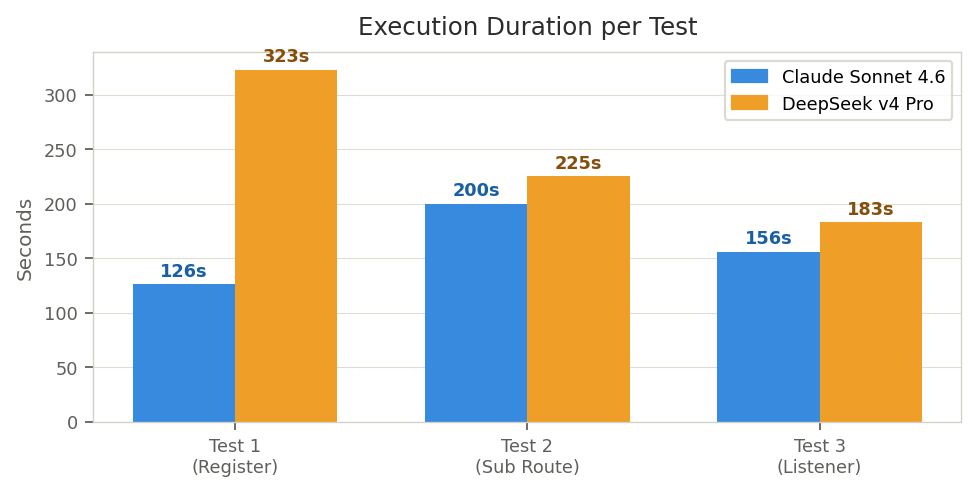
Claude completed the full suite in 483s vs DeepSeek's 733s — 34% faster overall. The gap is most pronounced in Test 1 (126s vs 323s), where DeepSeek's higher per-call latency compounded across 44 API calls.
| Claude T1 | DS4 T1 | Claude T2 | DS4 T2 | Claude T3 | DS4 T3 | Total | |
|---|---|---|---|---|---|---|---|
| Duration | 126s | 323s | 200s | 225s | 156s | 183s | C: 483s · DS: 733s |
API Calls
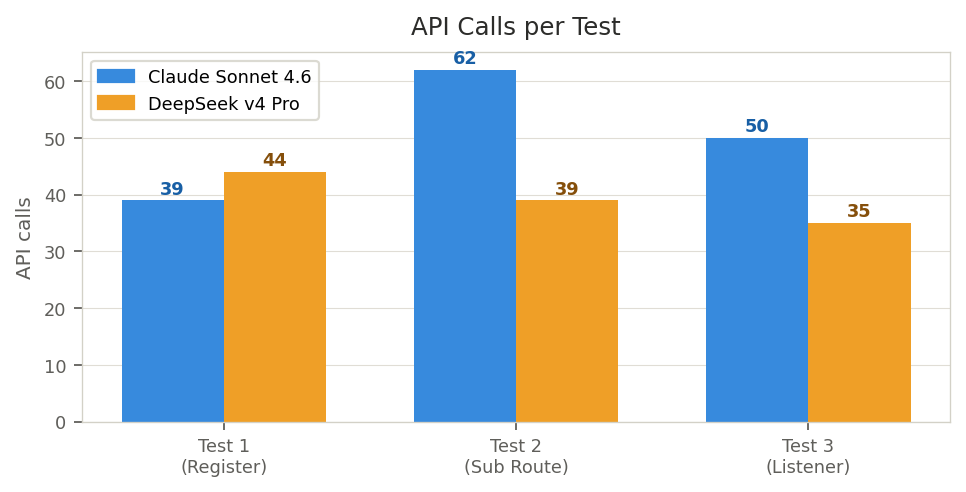
DeepSeek uses fewer calls in Tests 2 and 3 due to a less granular verification pattern. Claude's higher count reflects more thorough step-by-step auditing.
| Claude T1 | DS4 T1 | Claude T2 | DS4 T2 | Claude T3 | DS4 T3 | Total | |
|---|---|---|---|---|---|---|---|
| API calls | 39 | 44 | 62 | 39 | 50 | 35 | C: 151 · DS: 118 |
| Step log entries | 61 | 70 | 83 | 58 | 68 | 49 | C: 212 · DS: 177 |
Cache Performance
Both models have active caching — the mechanisms differ but both achieve high cache hit rates.
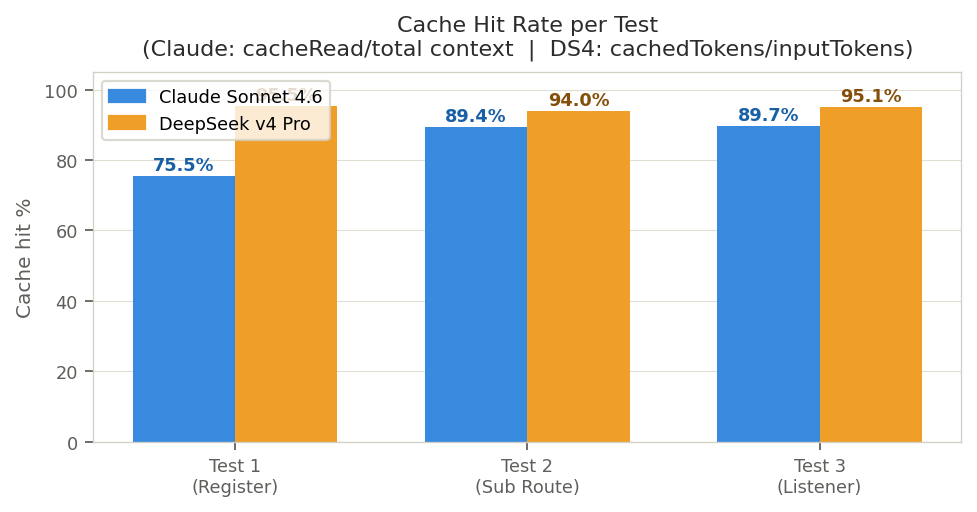
| Claude T1 | DS4 T1 | Claude T2 | DS4 T2 | Claude T3 | DS4 T3 | |
|---|---|---|---|---|---|---|
| Cache hit tokens | 425,494 | 595,584 | 678,932 | 487,552 | 510,033 | 398,848 |
| Full-rate tokens | 138,105 | 28,333 | 80,750 | 31,253 | 58,676 | 20,362 |
| Cache hit rate | 75.5% | 95.5% | 89.4% | 94.0% | 89.7% | 95.1% |
DeepSeek achieves a higher cache hit rate (94–95%) vs Claude (75–89%). This is because DeepSeek's cache covers the full accumulated conversation history, while Claude's cacheReadTokens grows from scratch each session and takes several turns to warm up (hence Test 1 is lower than T2/T3 for Claude).
Cache Hit Tokens per Step
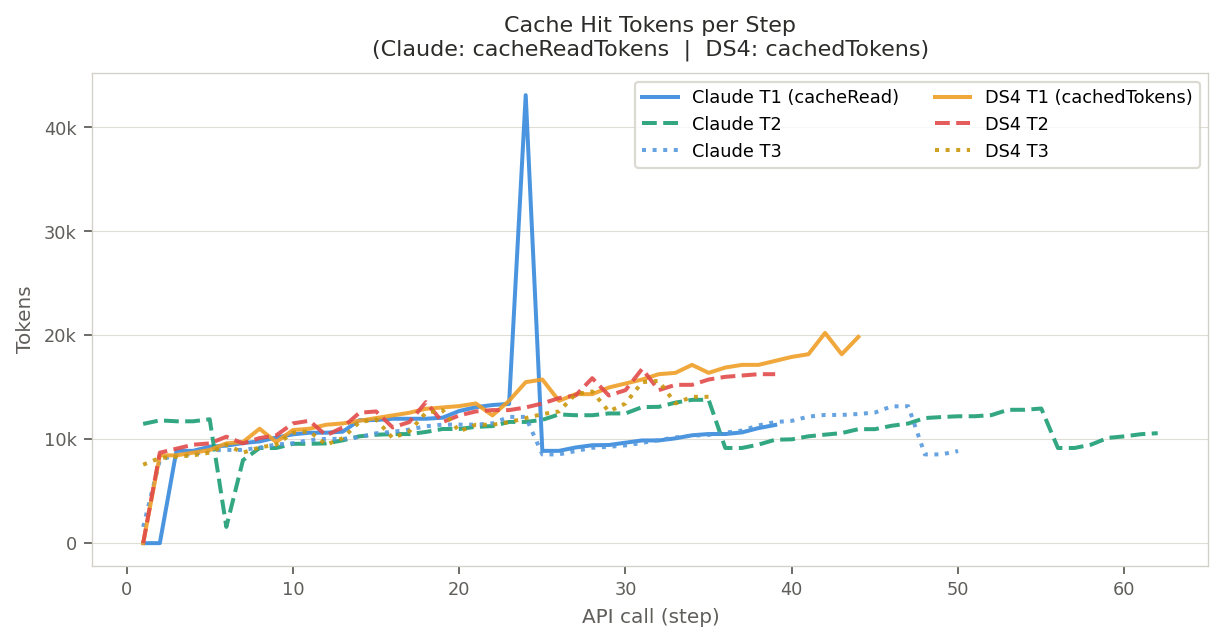
Claude's cache reads grow steadily through the session. DeepSeek's cached tokens start high (system prompt + tools are cached from step 2) and grow linearly as history accumulates — explaining the higher overall hit rate.
Full-Rate Billed Tokens per Step
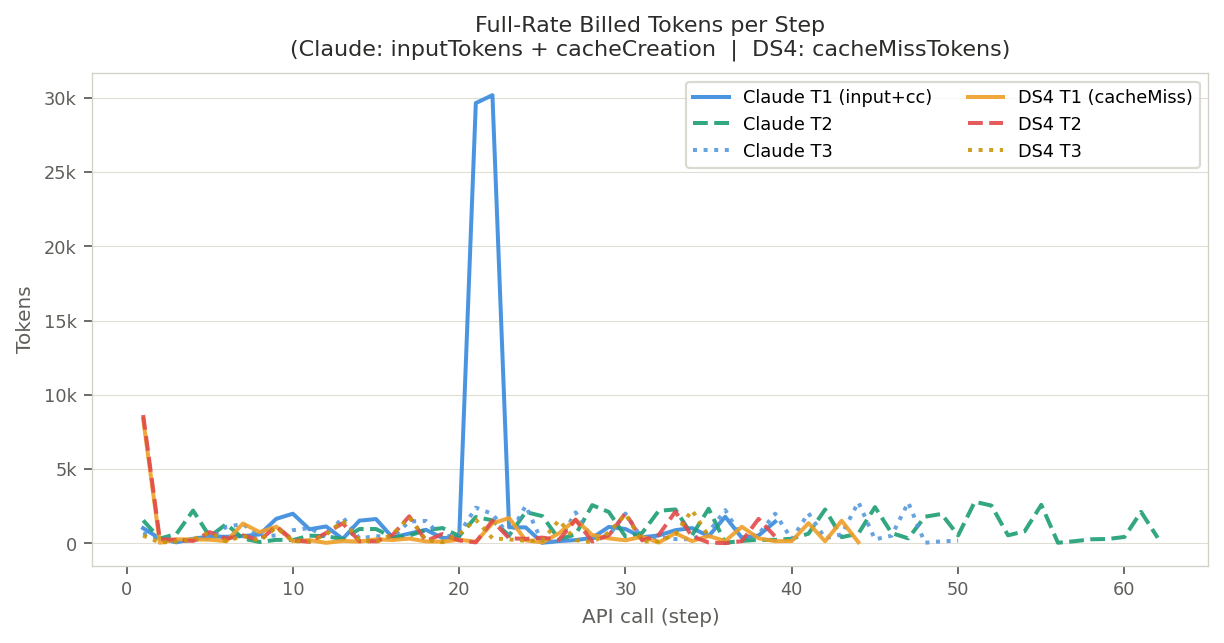
The key difference in token economics: Claude sends only new content (44–2,800 tokens per step at full rate after warm-up), while DeepSeek's cacheMissTokens are small too (40–2,200 per step) — both models bill surprisingly little at full rate per call once the cache is warm.
The large spike in Claude T1 steps 21–22 (~30k) is caused by a large ARIA tree snapshot from the registration form being absorbed into cache in that turn.
Token Breakdown Summary
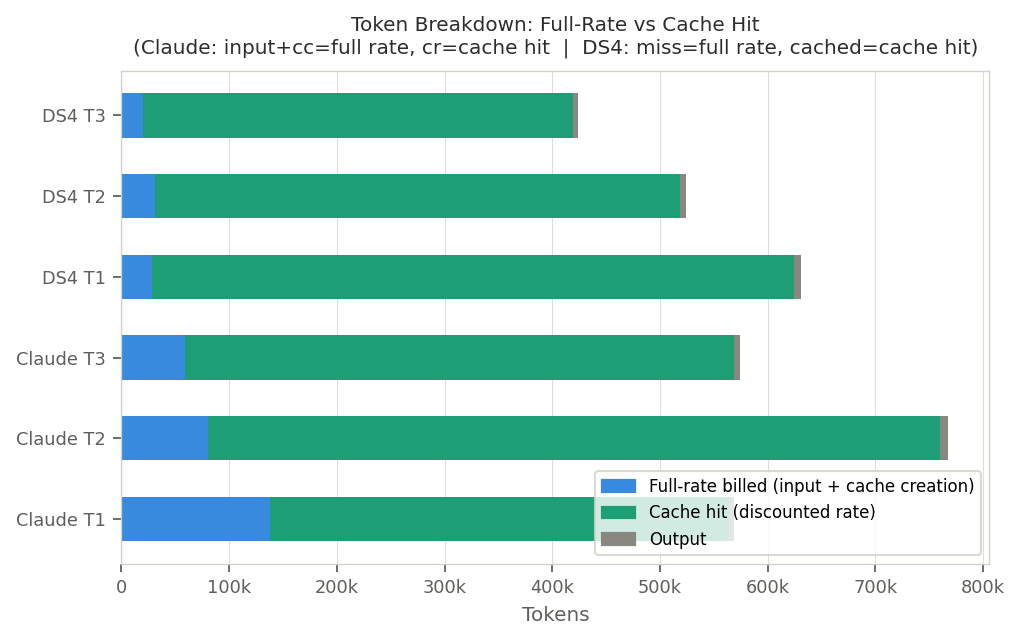
| Claude T1 | DS4 T1 | Claude T2 | DS4 T2 | Claude T3 | DS4 T3 | |
|---|---|---|---|---|---|---|
| Full-rate billed | 138,105 | 28,333 | 80,750 | 31,253 | 58,676 | 20,362 |
| Cache hit (discounted) | 425,494 | 595,584 | 678,932 | 487,552 | 510,033 | 398,848 |
| Output | 4,840 | 7,301 | 7,720 | 5,408 | 5,867 | 4,466 |
Claude's full-rate figure =
inputTokens+cacheCreationTokens
DS4's full-rate figure =cacheMissTokens
Claude's cache hit figure =cacheReadTokens
DS4's cache hit figure =cachedTokens
Output Tokens
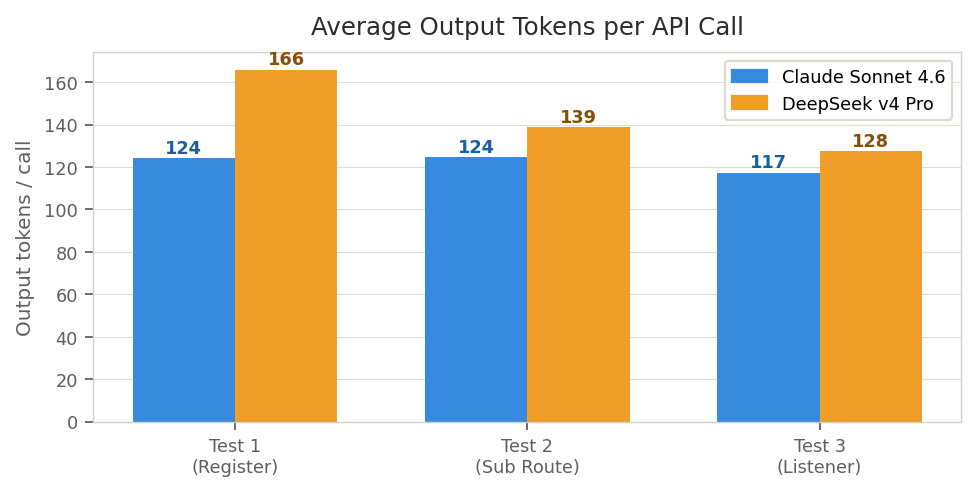
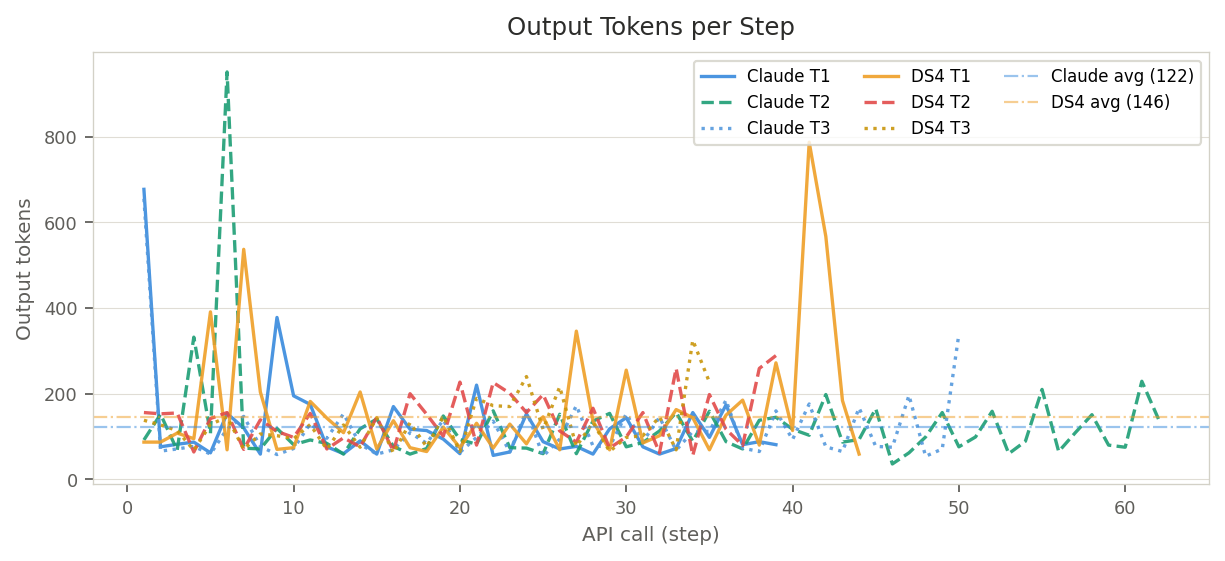
DeepSeek is consistently more verbose despite the same "1–2 sentence max" system prompt instruction:
| Claude T1 | DS4 T1 | Claude T2 | DS4 T2 | Claude T3 | DS4 T3 | Overall avg | |
|---|---|---|---|---|---|---|---|
| Avg output/call | 124 | 166 (+34%) | 125 | 139 (+11%) | 117 | 128 (+9%) | C: 122 · DS: 144 |
| Total output | 4,840 | 7,301 | 7,720 | 5,408 | 5,867 | 4,466 | C: 18,427 · DS: 17,175 |
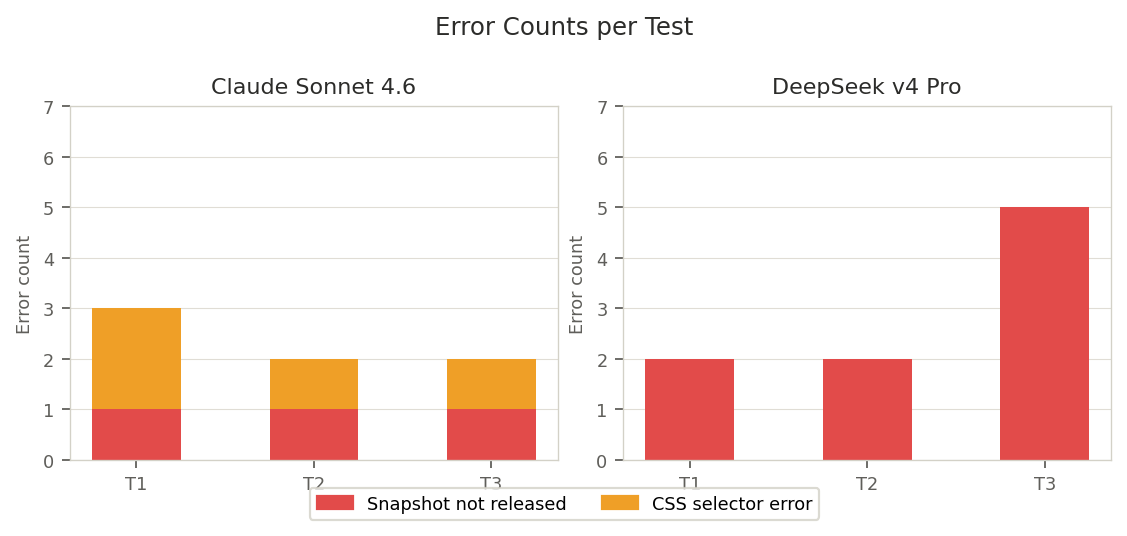
Errors and Issues
Key Takeaways
Both models have effective caching — DeepSeek's hit rate is higher.
DeepSeek achieves 94–95% cache hit rates from the second call onward (system prompt + tools cached immediately). Claude warms up more gradually, reaching 89–90% by Tests 2 and 3.
Full-rate billed tokens are small for both once cache is warm.
After the first call, both models bill surprisingly little at full rate per step — typically 40–2,000 tokens. The cost difference comes primarily from cache creation and model pricing, not from per-step miss volume.
Speed: Claude wins clearly.
34% faster overall (483s vs 733s), driven by lower per-call latency. DeepSeek's latency is higher regardless of token volume.
API calls: DeepSeek more efficient in Tests 2–3.
22% fewer total calls. Less granular verification pattern means fewer round trips but also less step-level auditability.
Output verbosity: Claude is more concise.
122 tokens/call average vs 144 for DeepSeek — 18% fewer. Both use the same system prompt brevity instruction.
Error patterns are complementary and both fixable via prompting.
Claude has a recurring CSS selector error on form submit buttons. DeepSeek has a worsening snapshot lifecycle issue on longer tests.